오늘은 Pymongo를 colab환경에서 실행하며 배운 것들을 적어보려한다.
!pip install pymongo먼저 colab에서 pymongo를 설치한다. 몽골에서 만든 거 아니다. ㅋㅋ 소소한 드립에 혼자 웃음 ㅎㅎ ^^ MongoDB를 파이썬환경에서 다룰 수 있도록 한다.
크게 데이터베이스라는것이 SQL vs NoSQL로 나뉜다.
Structured Query Language. 기본적으로 이 SQL은 관계형 데이터베이스 관리 시스템(RDBMS)이다.
(Relational DataBase Management System)

SQL이라 하면 데이터베이스용 프로그래밍 용어이기도 하고, 데이터 구조가 고정되어 있는 DB에서 사용된다.
(MySQL, Oracle, SQLite, PostgreSQL등 다양한 DB가 SQL 기반이다. )
데이터의 구조가 테이블로다가 이뤄져 있다. 그리고 그 테이블간 관계를 통해서 데이터를 쌓고 관리한다.
(테이블은 하나 이상의 열-행으로 이뤄져 있음.)
반면 NoSQL은 데이터의 구조가 고정되어 있지 않은 데이터베이스이다. (비관계형 데이터베이스).
웹 어플리케이션이 보편화되고 복잡해지면서 인기가 많아졌다고 한다. 여기는 TABLE형식으로 데이터를 쌓지 않는다. 문서(JSON), 키-값 쌍, 그래프 등 다양한 데이터를 저장할 수 있다. 큰 빅데이터 처리에 유리하지만 표준화된 쿼리언어가 없으며 데이터의 무결성을 직접 관리해야하는 단점도 있다.
(참고:https://www.whatap.io/ko/blog/173/)
from pymongo import MongoClient
# MongoDB 인스턴스에 연결 / client 인스턴스 생성
# client = MongoClient('mongodb://접속하려는주소:27117/')
client = MongoClient('mongodb://접속ID:비밀번호@접속하려는주소:27117/')
저 client가 제대로 생성되었다면 이제 db가 만들어진 것이고, db이름을 지으면서 접근할 수 있다 !!
굉장히 간편하게 된다.
# 데이터베이스 선택 (없으면 새로 생성됨)
db = client['tutorial_db_park']
# 여기선 테이블이 컬렉션 / 컬렉션 선택 (없으면 새로 생성됨)
collection = db['tutorial_collection']
# 문서 생성 및 삽입
document = {"name": "Son", "age": 30, "city": "Tottenham"}
collection.insert_one(document)
READ
현재까지 생성된 data를 조회하고 싶다면.
# 모든 문서 조회
for doc in collection.find():
print(doc)collection.find를 통해서 조회하면 된다.
조건을 걸고 조회할 수도 있다.
# 특정 조건에 맞는 문서 조회
query = {"city": "Tottenham"}
documents = collection.find(query)
for doc in documents:
print(doc)
CREATE
document = {"name": "Sam Altman", "age": 40, "country": "USA"}
collection.insert_one(document)insert_one을 통해서는 하나씩 데이터를 집어넣을 수 있다. key값을 " 이 쌍따옴표를 통해서 넣어줘야한다.
한 번에 여러개도 집어넣을 수 있다. 이때는 insert_many를 사용하면 되며, 하나의 리스트로 감싸줘야한다.
document = {"name": "Sam Altman", "age": 40, "country": "USA"}
document2 = {"name": "Elon Musk", "age": 50, "company": "TESLA"}
document3 = [document, document2]
collection.insert_many(document3)
UPDATE
# 문서 업데이트
collection.update_one(
{"name": "Sam Altman"}, #조건
{"$set": {"age": 42}}
)
# Sam Altman이 여러명 있으면 제일 처음에 발견된 Sam Altman 하나만 바뀜.
# 문서 업데이트
collection.update_one(
{"name": "Elon Musk"}, #조건
{"$set": {"country": "KOREA"}}
)
DELETE
collection.delete_one({"age": 42})이렇게 하면 나이 42살 먹은 사람이 삭제된다.
MongoDB에서는 다양한 쿼리 연산자를 사용할 수 있다.
뤼튼의 친절한 설명.
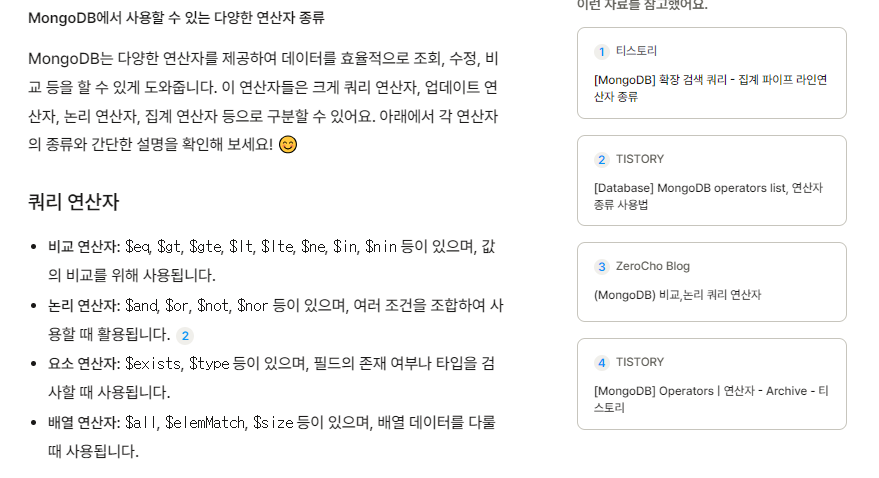
비교의 $eq는 값이 지정된 값과 동일한 경우 문서를 선택한다.
$gte는 값이 지정된 값보다 크거나 같은 경우에 문서 선택.
논리의 $and / 모든 조건 만족하는 문서 선택
$not / 주어진 조건 만족하지 않는 문서 선택
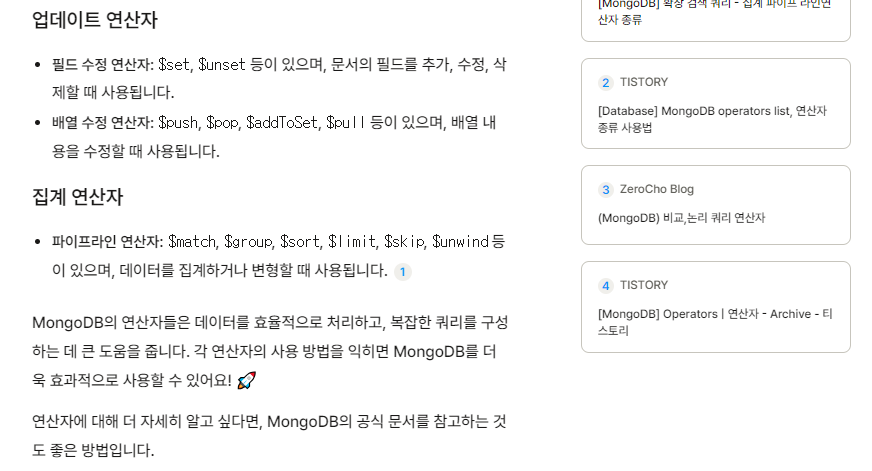
업데이트 $set / 지정된 필드의 값을 지정된 것으로 설정
집계 $group / 문서를 그룹화하고 집계해줌. (마치 sql의 group by)
$match / 지정된 조건을 만족하는 문서 선택.
$sort / 문서를 지정된 필드의 값에 따라 정렬.
$project / 지정된 필드만 포함하도록 문서 구조를 변환함.
연습
db = client['내거 이름']
collection = db['설정할 db이름']
# 기존 데이터 삭제
collection.delete_many({})
# 샘플 데이터 삽입
sample_users = [
{"name": "Apple", "email": "Apple@example.com"},
{"name": "Boe_china", "email": "Boe_china@example.com"},
{"name": "Cildren", "email": "Cildren@example.com"},
{"name": "T-robotics", "email": "robotics@example.com"},
{"name": "Intellian", "email": "Intellian@example.com"}
]
collection.insert_many(sample_users)
{'_id': ObjectId('6603d8684b86936db546392d'), 'name': 'Apple', 'email': 'Apple@example.com'}
{'_id': ObjectId('6603d8684b86936db546392e'), 'name': 'Boe_china', 'email': 'Boe_china@example.com'}
{'_id': ObjectId('6603d8684b86936db546392f'), 'name': 'Cildren', 'email': 'Cildren@example.com'}
{'_id': ObjectId('6603d8684b86936db5463930'), 'name': 'T-robotics', 'email': 'robotics@example.com'}
{'_id': ObjectId('6603d8684b86936db5463931'), 'name': 'Intellian', 'email': 'Intellian@example.com'}데이터 조회하면 이렇게 나온다. _id는 내가 지정하지 않았지만 알아서 생긴다.
pipeline = [
{"$project": {"_id": 0, "name": 1, "email": 1}}, #0은 False 1은 True 의미.
{"$sort": {"email": 1}} # 내림차순 : -1
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
$project 통해서 _id는 가져오지 않았다. name과 email만 가져왔다.
그리고 이메일에서 알파벳 오름차순으로 정리하라고 했다.
{'name': 'Apple', 'email': 'Apple@example.com'}
{'name': 'Boe_china', 'email': 'Boe_china@example.com'}
{'name': 'Cildren', 'email': 'Cildren@example.com'}
{'name': 'Intellian', 'email': 'Intellian@example.com'}
{'name': 'T-robotics', 'email': 'robotics@example.com'}
결과는 이렇게 나온다!
연습2
collection = db['parkbase']
# 기존 데이터삭제
collection.delete_many({})
# 샘플 데이터 삽입(단위는 억)
sample_users = [
{"name": "Alice", "age": 18, "Stock": 500},
{"name": "Bob", "age": 25, "Stock": 750},
{"name": "Charlie", "age": 35, "Stock": 1200},
{"name": "David", "age": 45, "Stock": 180},
{"name": "Eve", "age": 55, "Stock": 350},
{"name": "Frank", "age": 65, "Stock": 1000}
]
collection.insert_many(sample_users)
for doc in collection.find():
print(doc)
sample_user들은 이름, 나이, 그리고 주식을 몇억 가지고 있는지 나와있다.
Frank 같은경우 1000억을 보유하고 있다. (개부자네?)
양극화가 요새 아주 극심하다. 주식 보유수량을 통해 각 사람들의 재정상태를 표현하는 데이터를 추가해보겠다.
pipeline = [
{"$addFields": {
"Status": {
"$switch": {
"branches": [ #switch가 if문 역할을 함.
{"case": {"$gte": ["$Stock", 1000]}, "then": "Super Rich"},
{"case": {"$gte": ["$Stock", 500]}, "then": "Upper Crust"},
{"case": {"$gte": ["$Stock", 350]}, "then": "citizen"},
],
"default": "PEOPLE"
}
}
}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
Status라는 필드를 추가할거다.
switch는 if역할을 한다. switch의 내용을 살펴보면, case가 그 조건들을 지정하는거다.
주식이 1000억 이상이면 super rich, 500억 이상이면 upper crust, 350억 이상이면 citizen이다.
{'_id': ObjectId('6603dad64b86936db5463932'), 'name': 'Alice', 'age': 18, 'Stock': 500, 'Status': 'Upper Crust'}
{'_id': ObjectId('6603dad64b86936db5463933'), 'name': 'Bob', 'age': 25, 'Stock': 750, 'Status': 'Upper Crust'}
{'_id': ObjectId('6603dad64b86936db5463934'), 'name': 'Charlie', 'age': 35, 'Stock': 1200, 'Status': 'Super Rich'}
{'_id': ObjectId('6603dad64b86936db5463935'), 'name': 'David', 'age': 45, 'Stock': 180, 'Status': 'PEOPLE'}
{'_id': ObjectId('6603dad64b86936db5463936'), 'name': 'Eve', 'age': 55, 'Stock': 350, 'Status': 'citizen'}
{'_id': ObjectId('6603dad64b86936db5463937'), 'name': 'Frank', 'age': 65, 'Stock': 1000, 'Status': 'Super Rich'}
잘 분류된 것을 알 수 있다.